
Мы уже рассказывали о проекте для агрохолдинга Русагро по мониторингу состояния и условий хранения сахарной свеклы. Внедрение этого решения на нашей IoT-платформе позволяет компании видеть полную картину всех происходящих на поле процессов в реальном времени, оптимизировать и координировать работу техники, сокращать потери запасов сырья на 20%, обеспечивать рост производительности и прибыли.
Читать далееРубрика: AggreGate Network Manager
AggreGate управляет вышками связи по всему миру

Быстрое расширение сетей, увеличение количества пользователей значительно усложняют процесс управления телекоммуникационными и сотовыми вышками, требуя все больших операционных затрат. В такой ситуации необходимо оптимизировать и повысить эффективность работы с активами.
Многолетний опыт и уровень экспертизы Tibbo Systems на рынке телеметрии позволяют соответствовать самым высокими требованиями операторов связи. А решения идеально подходят для многопользовательской архитектуры вышек, делая возможным разделение услуг между несколькими провайдерами.
Читать далееНам доверяет МЧС России
Главное управление МЧС России по Тверской области объявило благодарность компании Tibbo Systems за успешное внедрение решения по мониторингу каналов связи и систем аварийного оповещения.
AggreGate осуществляет мониторинг и управление серверами, сетями, рабочими станциями и оборудованием конференц-связи, что значительно сократило расходы на диагностику сетей. Система точно указывает местоположение и первопричину возникших проблем. Кроме того, AggreGate позволил контролировать датчики радиации без дополнительных затрат.

Мы благодарны за оказанное доверие и также надеемся на дальнейшее плодотворное сотрудничество.
Вы можете ознакомиться с примером внедрения AggreGate Network Manager для МЧС России по ссылке.
AggreGate Network Manager контролирует сеть нефтегазовой компании Aramco
Компания Tibbo Systems совместно с Technology Leaders Co. Ltd. внедрила систему для мониторинга сети и набора датчиков объекта нефтегазовой компании Aramco (Саудовская Аравия).
Использование AggreGate с контроллерами Tibbo TPS позволило интегрировать различные виды оборудования в единую систему мониторинга. Датчики утечки воды, температуры и влажности, система пожарной сигнализации, система управления отоплением, вентиляцией и кондиционированием, ИБП и устройство для отпугивания грызунов были подключены через контроллеры Tibbo TPS со специальной прошивкой.
AggreGate Network Manager производит мониторинг такого стандартного сетевого оборудования, как серверы, маршрутизаторы, IPDU, виртуальные машины.
Также был интегрирован веб-интерфейс VMS. Это система с высоким уровнем интеграции инженерного и сетевого оборудования, простым и гибким интерфейсом для операторов и мощными инструментами для дальнейшего расширения системы администраторами.





Компания Tibbo Systems стала официальным спонсором конференции ИТ будущего компании Россети
Tibbo Systems совместно с партнером - компанией Inline Group - представила решение для мониторинга ИТ инфраструктуры AggreGate Network Manager на конференции ИТ будущего, организованной компанией Россети. Это были три отличных продуктивных дня, и мы хотим поделиться фото-отчетом с мероприятия.





















Мониторинг телекоммуникационных сетей уровня агрегации и уровня доступа
Видео иллюстрирует концепцию мониторинга сервисов в IP сети, которая опирается на корреляции событий топологии. Реакция на события получилась очень быстрой благодаря возможности настройки моментального опроса SNMP в AggreGate Network Manager.
В этой демонстрации IP-сервисы импортируются из системы инвентаризации стороннего производителя. Пользовательский интерфейс для демонстрации, в том числе список тревог о неисправностях/деградации и окно видео с IP-камеры, был построен с помощью интегрированного в AggreGate редактора UI.
Мониторинг ИТ инфраструктуры Российского университета дружбы народов
![]() AggreGate Network Manager контролирует беспроводную сеть Cisco и ИТ-инфраструктуру Российского университета дружбы народов.
AggreGate Network Manager контролирует беспроводную сеть Cisco и ИТ-инфраструктуру Российского университета дружбы народов.
Сморите новый пример внедрения на нашем сайте.
Вы также можете посмотреть другие case studies по мониторингу ит инфраструктуры, автоматизации производственных процессов и т. д.
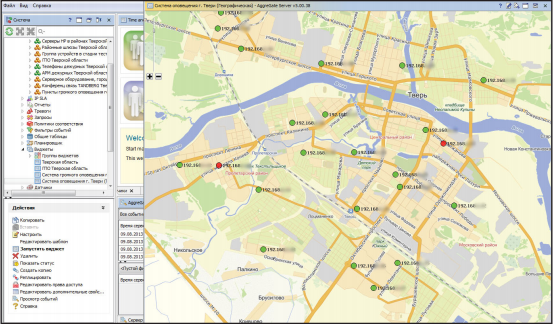
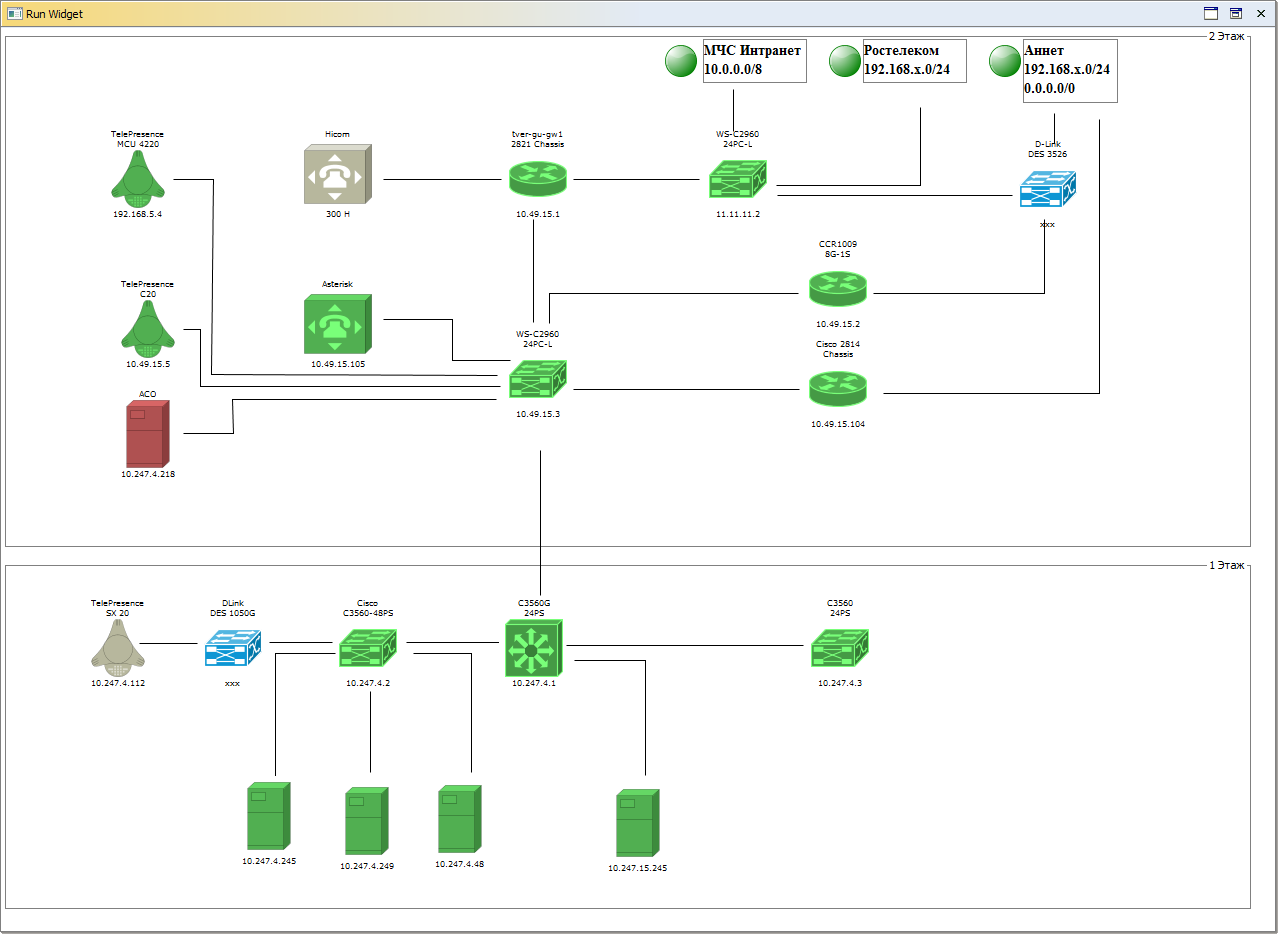
Мониторинг критически-важной инфраструктуры для МЧС России
Инженеры Tibbo успешно внедрили решение по мониторингу каналов связи и систем аварийного оповещения для МЧС России.
AggreGate осуществляет мониторинг и управление серверами, рабочими станциями, а также сетями и оборудованием конференц-связи. Это значительно сократило расходы на диагностику сетей, а новая система точно указывает местоположение и первопричину возникших проблем. Кроме того, AggreGate позволил контролировать датчики радиации без дополнительных затрат.
 |
 |
Сморите новый пример внедрения решения AggreGate.
Мониторинг и управление Java-приложениями (JMX)
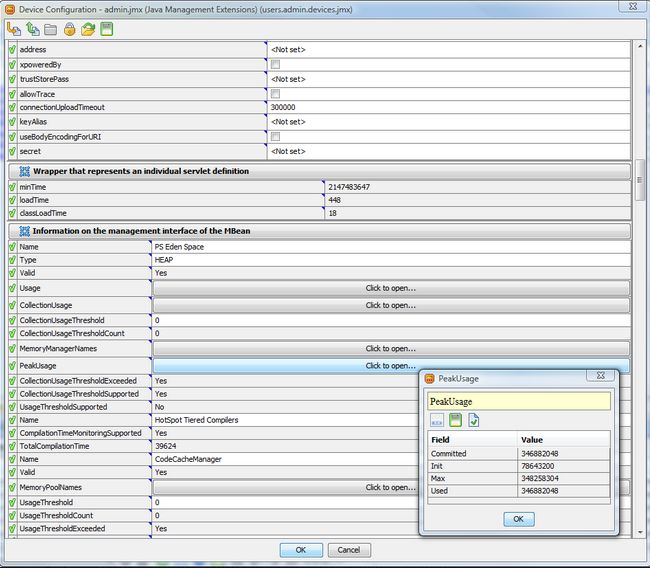 Читайте нашу новую статью Мониторинг и управление Java-приложениями (JMX) и узнайте о том, как AggreGate Network Manager осуществляет мониторинг сервисов, серверов приложений и обычных приложений, реализованных на Java, при помощи технологии Java Management Extensions (JMX).
Читайте нашу новую статью Мониторинг и управление Java-приложениями (JMX) и узнайте о том, как AggreGate Network Manager осуществляет мониторинг сервисов, серверов приложений и обычных приложений, реализованных на Java, при помощи технологии Java Management Extensions (JMX).
Вы также можете попробовать инструмент Java-мониторинга, скачав в разделе Загрузки бесплатную версию на 10 устройств.
Управление сетями с AggreGate
Знаете ли вы, что, кроме мониторинга любых сетевых устройств и сервисов, AggreGate может управлять ими различными способами? Чтобы узнать больше, читайте нашу новую статью на сайте Управление сетями.